Self Attention Mechanism
Self Attention Mechanism
Easy:
Imagine you’re at a big party with lots of friends, and everyone wants to talk to you at once It can be really hard to listen to one friend when another is shouting in your ear. But what if you had superpowers that allowed you to focus on one friend’s voice at a time, even though they’re all talking? You could choose who to listen to based on what you want to hear or who you want to talk to next. This is similar to how the Self-Attention mechanism works in deep learning.
Deep learning is like teaching a computer to understand and respond to the world around us, just like how we understand and interact with our friends. However, computers don’t naturally understand language or images the way humans do. They need help figuring out which parts of a sentence or image are important for understanding the whole thing.
The Self-Attention mechanism is like those superpowers for computers. It helps the computer decide which parts of an image or sentence are most important for understanding the whole thing, similar to focusing on one friend’s voice at the party. Here’s how it works:
- Focusing on Important Parts: Instead of looking at everything at once, the Self-Attention mechanism allows the computer to focus on specific parts of an image or sentence. It decides which parts are more important for understanding the whole thing.
- Choosing What to Pay Attention To: Just like choosing which friend to listen to at the party, the Self-Attention mechanism lets the computer decide which parts of the image or sentence are most relevant. This could be because those parts contain key details or because they’re related to what the computer is currently trying to understand.
- Improving Understanding: By focusing on the most important parts, the computer can better understand the whole image or sentence. It’s like understanding a joke by paying attention to the punchline, even if the rest of the conversation is going on around it.
- Used in Many Places: The Self-Attention mechanism is used in many types of deep learning models, especially in natural language processing (for understanding sentences) and computer vision (for understanding images). It helps these models become better at recognizing patterns, understanding languages, and even generating creative content like stories or art.
So, the Self-Attention mechanism is like having superpowers that allow computers to focus on the most important parts of what they’re learning, helping them understand and respond to the world around them just like we do with our friends at a party.
Another easy example:
Imagine you are in a classroom with a lot of students, and the teacher is telling a story. Sometimes, to understand the story better, you need to pay attention to different parts of what the teacher is saying at the same time. For example, you need to remember the names of the characters, what they are doing, and where the story is happening.
What Does Self Attention Do?
Self Attention in a neural network is like having a superpower that allows the network to pay attention to all parts of a story (or a sentence) at once. It helps the network understand how different words in a sentence are related to each other, no matter where they are in the sentence.
How Does It Work?
- Understand Relationships: Imagine each word in a sentence has a little light bulb above it. Self Attention helps the network decide which light bulbs need to be the brightest. This means it figures out which words are most important to understanding the sentence.
- Focus on Important Words: If the sentence is “The cat sat on the mat,” the network might realize that “cat” and “sat” are closely related, so their light bulbs should shine brighter. This helps the network understand that it’s the cat doing the sitting.
- Combine Information: The network looks at all the words together and combines their meanings. This is like putting together pieces of a puzzle to see the whole picture.
Why Is It Important?
Just like you need to pay attention to different parts of the story to understand it, the Self Attention Mechanism helps the neural network understand the whole meaning of sentences by looking at all the words together. This makes the network really good at tasks like understanding language, translating languages, and even creating new sentences.
Summary
The Self Attention Mechanism in deep learning is like a superpower that helps a neural network focus on the important parts of a sentence all at once. It helps the network understand how words in a sentence are related, making it much better at understanding and generating language.

Moderate:
The Self-Attention mechanism in deep learning is a powerful tool that allows models to focus on different parts of an input (like an image or a sentence) when producing an output. It’s like giving the model the ability to pay attention to specific details that are relevant to the task at hand, ignoring the rest. This mechanism has been particularly influential in advancing the state-of-the-art in various domains, including machine translation, text summarization, and image recognition.
How Does It Work?
- Computing Attention Scores: The first step in the self-attention process involves computing scores that indicate how much attention should be paid to each part of the input relative to every other part. These scores are computed based on the relationships between different elements within the input.
- Softmax Function: After calculating the scores, a softmax function is applied to convert these scores into probabilities. This ensures that the sum of all attention probabilities equals 1, allowing the model to distribute its attention across the input in a meaningful way.
- Weighted Sum: Each element of the input is then multiplied by its corresponding attention probability. This weighted sum creates a new representation where important elements receive higher weights, amplifying their contribution to the final output.
- Multiple Layers: The self-attention mechanism can be applied multiple times in sequence, allowing the model to refine its focus and capture complex dependencies between different parts of the input.
Applications
- Natural Language Processing (NLP): In NLP tasks like machine translation, the self-attention mechanism enables the model to understand the context of words in a sentence by focusing on relevant words, regardless of their distance from the target word.
- Computer Vision (CV): In CV tasks, self-attention allows models to focus on specific regions of an image that are relevant to the task, improving the model’s ability to recognize objects or perform semantic segmentation.
- Generative Models: Self-attention mechanisms are also used in generative models to create coherent and contextually relevant outputs, whether it’s generating text, images, or music.
Advantages
- Flexibility: Self-attention can be applied to inputs of varying lengths and structures, making it versatile for different types of data.
- Efficiency: Despite its power, self-attention mechanisms can be implemented efficiently, thanks to optimizations like the use of learned linear transformations and parallelizable computations.
- Improved Performance: By enabling models to focus on relevant details, self-attention often leads to significant improvements in performance on a wide range of tasks.
In essence, the Self-Attention mechanism revolutionizes how deep learning models process and understand input data by allowing them to dynamically focus on the most relevant parts, enhancing their ability to perform complex tasks across various domains.
Hard:
Self-Attention Mechanism is a crucial component in deep learning models, particularly in transformer architectures. It allows the model to dynamically focus on different parts of the input data based on their relevance to the context. This mechanism is essential for tasks like machine translation, image captioning, and dialogue generation, where the model needs to capture long-range dependencies and relationships between different parts of the input sequence.
Key Components
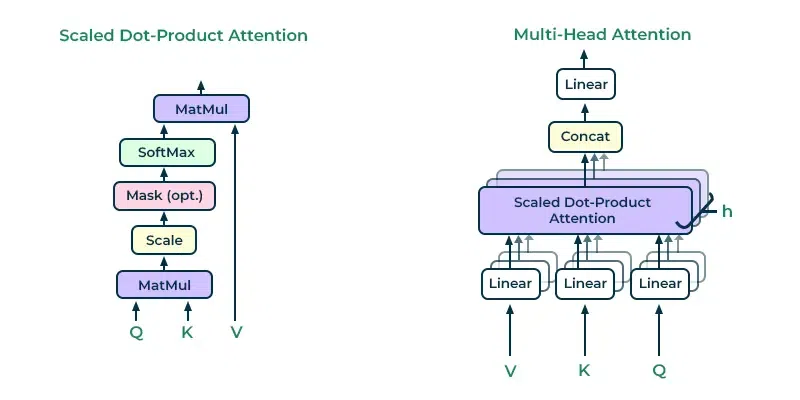
The self-attention mechanism involves three main components:
- Query (Q): This matrix helps focus on the word of interest.
- Key (K): This matrix measures the relevance between words.
- Value (V): This matrix provides the context that will be combined to create the final contextual representation of the focus.
How Self-Attention Works
Here is a step-by-step explanation of how self-attention works:
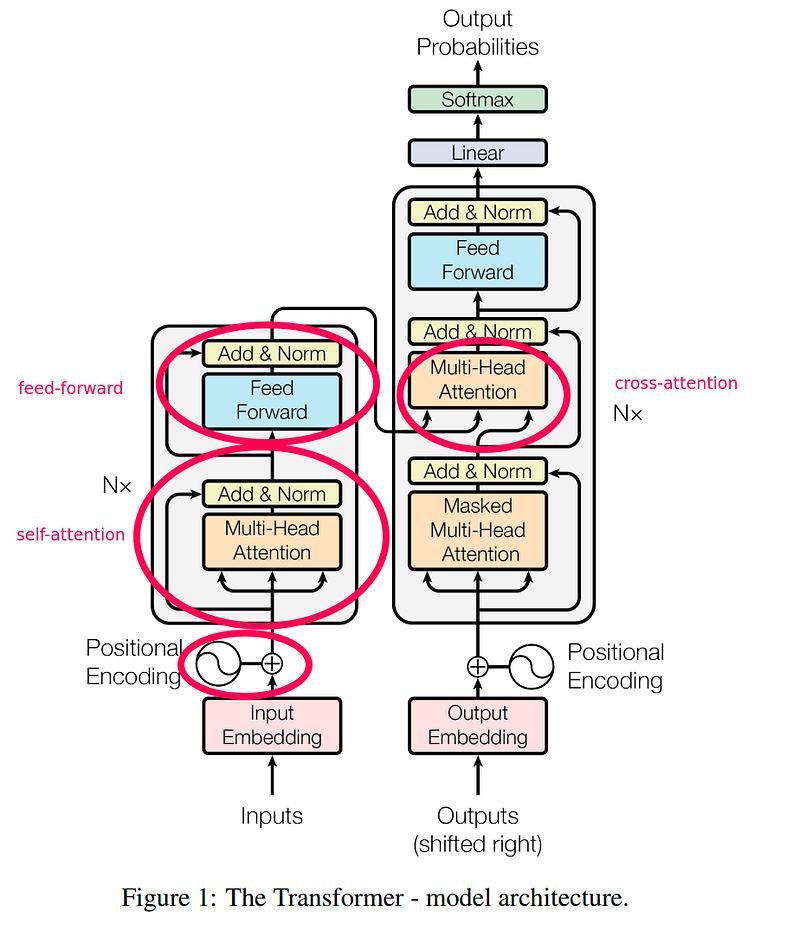
- Input Embeddings: The input sequence is converted into word embeddings, which are numerical representations of the words. These embeddings also incorporate positional information to preserve the order of the words.
- Multi-Head Attention: The transformer architecture uses a multi-head attention mechanism, which consists of multiple self-attention layers running in parallel. Each attention layer has its own set of Q, K, and V matrices.
- Scaled Dot-Product Attention: Within each self-attention layer, the Q, K, and V matrices are used to calculate the scaled dot-product attention. This involves measuring the similarity scores between the query and key vectors and then using these scores to compute the weighted sum of the value vectors.
- Feed-Forward Neural Networks: The output from the multi-head attention is passed through a position-wise feed-forward neural network, which consists of two linear layers separated by a non-linear activation function (e.g., ReLU). This step helps the model learn more complex patterns and relationships within the input sequence.
- Layer Normalization and Residual Connections: The transformer architecture uses layer normalization and residual connections to stabilize the training process and improve the model’s performance.
Benefits
The self-attention mechanism offers several benefits:
- Improved Contextual Understanding: It allows the model to capture long-range dependencies and relationships between different parts of the input sequence.
- Flexibility: It can be applied to different types of data, such as text, images, and audio.
- Efficiency: It can be parallelized across multiple attention heads, making it computationally efficient.
Conclusion
Self-Attention Mechanism is a powerful tool in deep learning models, particularly in transformer architectures. It enables the model to dynamically focus on different parts of the input data based on their relevance to the context, leading to improved performance and contextual understanding.
If you want you can support me: https://buymeacoffee.com/abhi83540
If you want such articles in your email inbox you can subscribe to my newsletter: https://abhishekkumarpandey.substack.com/
A few books on deep learning that I am reading:



Comments
Post a Comment