Mid Level Depth Aware Semantic Segmentation
Mid Level Depth Aware Semantic Segmentation
Easy:
Imagine you’re playing a game where you have to draw a picture of a scene, but you can only use one color for everything. Now, imagine you’re playing this game in a room with a lot of different things in it, like toys, a bed, and a toy box. You want to make sure that your drawing looks realistic, so you need to figure out how to use your one color to make everything look like it’s in the right place and at the right distance from each other.
Mid Level Depth Aware Semantic Segmentation is like that game, but for computers. Computers use something called “machine learning” to help them understand and draw pictures of real-world scenes. When they do this, they need to know where everything is and how far away it is from the camera. This is what we call “depth” in computer vision.
But there’s a twist! Just like in your game, the computer can only use one color for everything. So, it needs to figure out what each thing in the scene is (like a toy, a bed, or a toy box) and then decide on the right color to use for it. This is what we call “semantic segmentation.”
So, Mid Level Depth Aware Semantic Segmentation is like playing a game where you have to draw a realistic picture of a room with toys, a bed, and a toy box, using only one color, and you also have to figure out where everything is and how far away it is from you. It’s a bit tricky, but computers are really good at it!

Moderate:
Mid Level Depth Aware Semantic Segmentation is a mouthful, but it basically means a computer program can “see” and understand pictures better by using two types of information:
- Color and Brightness: This is like the normal picture you see, showing things like people, objects, and the environment.
- Depth: Imagine a special map that tells the computer how far away things are, like a 3D ruler.
Here’s how it works:
- Understanding the picture: The program analyzes the colors and brightness to recognize things like cars, houses, trees, etc., just like you would.
- Adding depth information: But it also has an extra superpower — it can see the “depth map,” which tells it the distance to objects. This helps it understand the size and position of things better.
- Putting it all together: By combining the color and depth information, the program can understand the picture in more detail. It can tell the difference between a small toy car close-up and a real car far away, or between a person standing in front of a tree and the tree itself.
Think of it like this:
- You use your eyes to see colors and shapes, but your brain also uses how far away things seem to figure out what’s happening.
- Similarly, Mid Level Depth Aware Semantic Segmentation helps computers “see” the world in a more nuanced way, just like we do.
This technology is used in many applications, such as:
- Self-driving cars: Understanding the distance and location of objects helps cars navigate safely.
- Robots: Robots can better interact with their environment by knowing how far away things are.
- Virtual reality: Creating more realistic and immersive virtual worlds.
So, even though it’s a complex term, Mid Level Depth Aware Semantic Segmentation is basically a way for computers to see the world in a more “3D” way, helping them understand and interact with the environment better.
Hard:
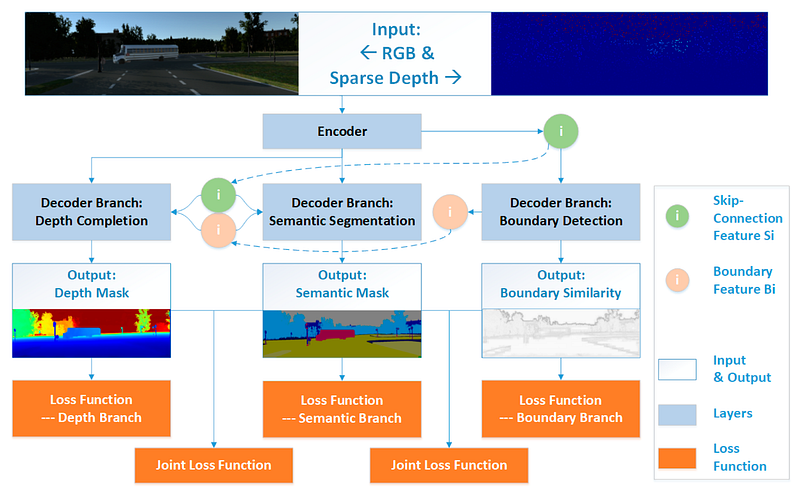
Mid-Level Depth Aware Semantic Segmentation is a sophisticated technique used in computer vision, specifically in the field of image processing and machine learning. It’s designed to analyze and categorize parts of an image into different objects or “semantic” categories, while also understanding the spatial relationships between these objects, such as their depth in the scene. This is crucial for tasks like autonomous driving, where understanding the environment in 3D is essential for safe navigation.
Here’s a simplified breakdown of how it works:
- Semantic Segmentation: This is the process of dividing an image into segments, where each segment is classified into a specific category, such as “car,” “tree,” or “person.” It’s like labeling each part of a picture to tell what it is.
- Depth Awareness: This part is about understanding how far away each object is from the camera. It’s like knowing how close or far something is in the real world. This is important because it helps in understanding the 3D structure of the scene.
- Mid-Level: This refers to the level of detail the algorithm works at. Mid-level means it’s somewhere between the very detailed (like recognizing individual leaves on a tree) and the very general (like just knowing it’s a tree). It’s a balance between accuracy and computational efficiency.
- Integration: The algorithm combines semantic segmentation with depth awareness to create a detailed, 3D understanding of the scene. It’s like having a map that not only tells you what’s in the room but also where everything is in relation to each other.
In practical terms, this technology is used in applications like autonomous vehicles, where it’s crucial to understand the environment in 3D to navigate safely. By accurately segmenting the scene and understanding the depth of objects, the vehicle can predict the movement of other objects, like pedestrians or other cars, and plan its path accordingly.
For example, if a car is detected in the image, the algorithm will not only identify it as a car but also estimate its distance from the vehicle. This information is crucial for making safe driving decisions, such as whether to change lanes or slow down.
In summary, Mid-Level Depth Aware Semantic Segmentation is a complex but powerful technique that allows computers to understand and interact with the world in a way that’s similar to how humans do, but with the added benefit of being able to process and analyze images and scenes in real-time.



Comments
Post a Comment