NVIDIA Collective Communications Library(NCCL)
NVIDIA Collective Communications Library(NCCL)
Easy:
Imagine you and your friends are working on a giant puzzle together. The puzzle is so big, it takes all of you to put it together. To win, you need to share the pieces you have and work together on different parts.
Normally, you might just pass the pieces around one by one. But that would take forever!
NCCL is like a super-powered way to share puzzle pieces. It lets everyone see all the pieces at the same time, almost like magic! This way, you can all work on different parts of the puzzle much faster.
Here’s how it works with computers:
- Instead of a puzzle, imagine you have a giant picture to color.
- Your computer splits the picture into smaller sections, like you might each get a section of the puzzle.
- Different parts of your computer, like powerful graphics chips called GPUs, color their sections.
- NCCL helps the GPUs share their colored sections with each other really quickly.
- By seeing what everyone else colored, the GPUs can work together to color the whole picture much faster than if they worked alone.
This is especially helpful for things like training powerful AI models, which require a lot of information sharing between different parts of the computer. NCCL makes sure everything works together smoothly, just like you and your friends working together on that giant puzzle!

Moderate:
The NVIDIA Collective Communications Library (NCCL) is a software library developed by NVIDIA that facilitates high-performance multi-GPU and multi-node communication. It provides primitives for collective communications such as all-gather, all-reduce, reduce, broadcast, and gather across multiple GPUs and nodes connected via NVLink or InfiniBand. These operations are essential for training deep learning models on distributed systems where multiple GPUs or nodes are used to process large amounts of data simultaneously.
Here’s a breakdown of its key features and benefits:
High-Performance Communication
- Optimized for NVIDIA Hardware: NCCL is designed specifically for NVIDIA GPUs, taking advantage of NVLink technology for direct GPU-to-GPU communication, significantly reducing latency and increasing bandwidth compared to CPU-based communication over PCIe.
- Efficient Data Transfer: It implements state-of-the-art algorithms for efficient data transfer between GPUs, minimizing memory transfers and optimizing data movement patterns.
Scalability Across Multiple Nodes
- Multi-Node Support: Beyond single-node configurations, NCCL supports multi-node communication, enabling large-scale distributed training of neural networks across clusters of GPUs.
- Fault Tolerance: It includes mechanisms for handling failures, ensuring that the system can recover gracefully from node or GPU crashes.
Simplified Development
- Easy Integration: NCCL is integrated into popular deep learning frameworks like TensorFlow, PyTorch, and MXNet, simplifying the development of distributed applications.
- Automatic Optimization: For many common scenarios, NCCL automatically optimizes the communication pattern, eliminating the need for manual tuning.
Use Cases
- Deep Learning Training: The most common use case for NCCL is in distributed training of deep learning models, where multiple GPUs or nodes work together to train on large datasets.
- High-Performance Computing (HPC): Beyond deep learning, NCCL can be used in HPC applications that require fast, scalable inter-GPU communication.
In summary, NCCL is a powerful tool for developers working on distributed computing applications, especially those involving machine learning or high-performance computing, by providing efficient and scalable communication primitives optimized for NVIDIA hardware.
Hard:
The NVIDIA Collective Communications Library (NCCL) is a library that provides optimized communication primitives for NVIDIA GPUs and networking. It is designed to facilitate efficient communication between multiple GPUs within a node and across nodes, which is crucial for applications such as deep learning training on multi-GPU and multi-node systems.
Key Features
- Collective Communication Primitives: NCCL provides a range of collective communication primitives, including:
All-Gather: Each GPU sends data to every other GPU.
All-Reduce: Each GPU combines its data with the data from other GPUs to produce a final result.
Broadcast: One GPU sends data to all other GPUs.
Reduce: Each GPU combines its data with the data from other GPUs to produce a final result, but only one GPU receives the final result.
Reduce-Scatter: Each GPU combines its data with the data from other GPUs to produce a final result, and then each GPU receives a part of the final result. - Point-to-Point Send and Receive: NCCL also supports point-to-point send and receive operations, which allow for scatter, gather, or all-to-all operations.
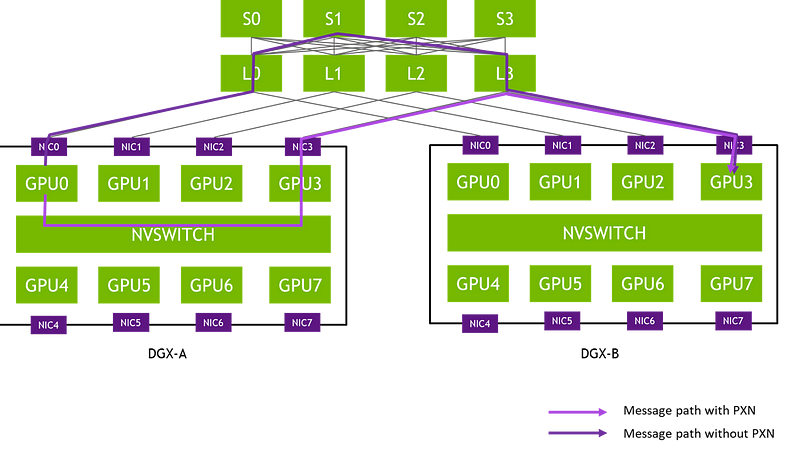
- Topology-Aware: NCCL is designed to be topology-aware, which means it can optimize communication paths based on the physical connections between GPUs. This includes support for PCIe, NVLink, InfiniBand, and Ethernet interconnects.
- High Performance: NCCL is optimized for high bandwidth and low latency, making it suitable for applications that require fast data transfer between GPUs.
- Ease of Programming: NCCL provides a simple C API that can be easily accessed from various programming languages. It closely follows the popular collectives API defined by MPI (Message Passing Interface), making it natural for developers familiar with MPI to use.
- Compatibility: NCCL is compatible with a variety of multi-GPU parallelization models, including single-threaded, multi-threaded, and multi-process applications.
How NCCL Works
NCCL optimizes communication by:
- Minimizing Latency: Using efficient algorithms and hardware capabilities to reduce the time it takes for data to travel between GPUs.
- Maximizing Bandwidth: Ensuring that data transfer utilizes the maximum available bandwidth, allowing large amounts of data to be communicated quickly.
- Overlap Communication and Computation: Enabling GPUs to perform computations while simultaneously communicating with other GPUs, which helps in hiding communication latency.
Performance Improvements
NCCL has seen significant performance improvements in recent releases, including:
- Up to 2x Peak Bandwidth: NCCL 2.12 and later versions support in-network all-reduce operations utilizing SHARPV2, which can achieve up to 2x peak bandwidth.
- InfiniBand Adaptive Routing: NCCL 2.12 and later versions include InfiniBand adaptive routing, which reroutes traffic to alleviate congested ports and optimize network traffic.
- Topology Support: NCCL supports various interconnect technologies, including PCIe, NVLink, InfiniBand, and Ethernet, as well as AMD, ARM, PCI Gen4, and IB HDR topologies.
Applications of NCCL
NCCL is widely used in:
- Deep Learning: Training large neural networks where data and model parameters need to be exchanged frequently between GPUs.
- Scientific Simulations: Performing large-scale simulations that require synchronized computations across multiple GPUs.
- High-Performance Computing (HPC): Applications that demand high computational power and need to distribute workloads across multiple GPUs for efficiency.
In summary, the NVIDIA Collective Communications Library (NCCL) is a powerful tool that enables efficient, high-speed communication between multiple GPUs, making it essential for many modern computing tasks that require parallel processing and large-scale computations.
Comments
Post a Comment