HardSwish activation function
HardSwish activation function
Easy:
Alright, let’s imagine you’re playing a game where you have to catch butterflies. But instead of using a net, you have a magical wand that can do something special: it can change how fast or slow you move towards the butterfly.
Now, there’s a trick to this wand. If you try to move too quickly, it might scare away the butterfly. And if you move too slowly, you’ll never catch up So, you need to find just the right speed to catch your butterfly.
The HardSwish activation function is like that magical wand, but for computers. Computers use these functions to help them understand and process information, much like how you need to find the right speed to catch a butterfly.
Here’s how it works: Imagine you have a scale that measures how happy you feel about catching a butterfly. On one side, you have moving too fast (which makes you scared), and on the other side, you have moving too slow (which makes you bored). The HardSwish activation function helps the computer find a spot in the middle, where it feels just right — not too excited, not too bored, but happy enough to keep going.
So, in simple terms, the HardSwish activation function helps computers find the perfect pace to understand and work with information, just like finding the right speed to catch a butterfly.

Moderate:
The HardSwish activation function is a mathematical operation used in machine learning models, particularly in neural networks, to introduce non-linearity into the model. This means it allows the model to learn more complex patterns by transforming its inputs in a specific way before making decisions or predictions. Let’s break down what makes the HardSwish unique and how it works:
What Does Activation Mean?
In the context of neural networks, an “activation function” determines whether a neuron should be activated (i.e., output a value) based on its input. Think of neurons as tiny decision-makers within the network. They take in information, process it through the activation function, and then either pass along the processed information or stop it from doing so.
Why Do We Need Non-Linearity?
Neural networks are built to mimic the human brain’s ability to recognize patterns and make decisions. However, without introducing non-linearity, a neural network would essentially be a linear model, capable only of learning relationships between inputs that form straight lines. Real-world problems, however, often involve complex, non-linear relationships. By incorporating non-linearity through activation functions, neural networks can learn and model these complexities.
Why Is It Called “Hard”?
The term “hard” in HardSwish comes from the fact that it is a piecewise function with two pieces: one for positive values and another for negative values. This “hardness” refers to the sharp transition from returning 0 to returning the input value without any gradient (slope) in between, unlike smoother functions like the regularized ReLU (ReLU).
Benefits of HardSwish
- Simplicity: HardSwish is computationally efficient and easier to implement compared to some other activation functions.
- Performance: It has been found to offer competitive performance in various tasks, including image recognition, without requiring as much computational power as some other methods.
- Memory Efficiency: Since it doesn’t require storing gradients during backpropagation (a key part of training neural networks), it can lead to memory savings.
Conclusion
The HardSwish activation function is a practical choice for many applications due to its simplicity, efficiency, and effectiveness. It plays a crucial role in enabling neural networks to learn and model complex patterns in data, much like how understanding and applying the right strategy can significantly impact one’s ability to solve puzzles or play games.
Hard:
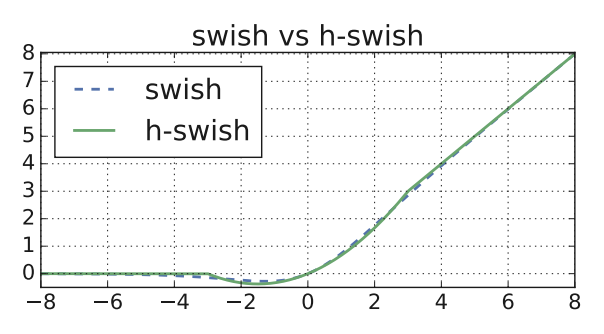
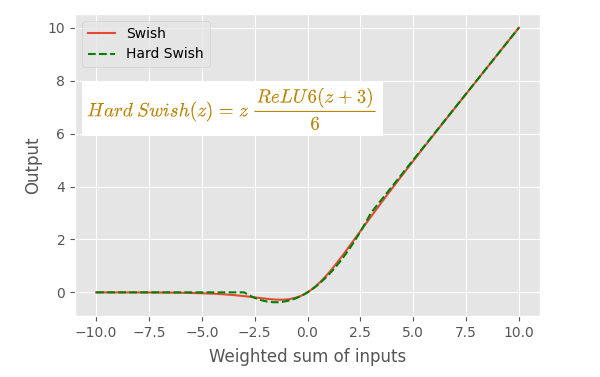
The HardSwish activation function is a piecewise linear function used in artificial neural networks. It serves as a replacement for the Swish function, offering a computationally efficient alternative while maintaining performance advantages.
How it Works
The HardSwish function is defined as follows:
h-swish(x) = x * ReLU6(x + 3) / 6
where:
- `x` is the input value
- `ReLU6` is the Rectified Linear Unit 6 function, which outputs `x` if `x` is between 0 and 6, 0 if `x` is negative, and 6 if `x` is greater than 6.
Visual Representation
The HardSwish function can be visualized as a combination of three linear segments:
1. For `x < -3`, the output is 0.
2. For `-3 <= x <= 3`, the output is a linear function of `x`.
3. For `x > 3`, the output is `x`.
Advantages
- Computational Efficiency: HardSwish is computationally efficient compared to the Swish function, as it uses simple arithmetic operations instead of complex exponential functions. This makes it particularly well-suited for resource-constrained environments, such as mobile devices.
- Performance: Despite its simplicity, HardSwish has been shown to perform comparably to or even better than the Swish function in various tasks, such as image classification.
- Non-linearity: Like other activation functions, HardSwish introduces non-linearity into neural networks, enabling them to learn complex patterns and relationships in data.
Applications
HardSwish is commonly used in deep neural networks, particularly those designed for mobile devices or other platforms where computational efficiency is a concern. It has been successfully employed in various models, including MobileNetV3, which is known for its efficient architecture and good performance on mobile devices.
Key Points
- HardSwish is a computationally efficient alternative to the Swish activation function.
- It is defined as a piecewise linear function.
- HardSwish offers good performance while being computationally efficient.
- It is commonly used in deep neural networks designed for resource-constrained environments.



Comments
Post a Comment