Bidirectional Encoder Representations from Transformers (BERT) Encoder
Bidirectional Encoder Representations from Transformers (BERT) Encoder
Easy:
Imagine you have a magical book that can understand any language spoken in the world. Not only does it understand, but it also remembers everything you’ve ever read in it. This magical book is like BERT, but instead of a physical book, it’s a tool used by computers to understand and remember text.
Now, suppose you want to ask this magical book about a word or a sentence. Instead of just telling you what it means, it gives you a whole story or explanation that helps you understand why it’s important or how it fits into the world. That’s exactly what BERT does with words and sentences — it understands them deeply and provides rich explanations.
But here’s the cool part: BERT doesn’t just do this for one person at a time. It can help millions of people at once by analyzing lots of texts and learning from them. This way, it gets smarter over time and can give better answers to questions about text.
So, a BERT encoder is like the smartest, most helpful magical book that exists, but for computers. It helps computers understand and remember text in a way that’s incredibly useful for tasks like searching the internet, translating languages, and even answering tricky questions about what a word really means based on lots of examples it has seen before.
Another easy example:
Imagine you have a super-smart robot friend named BERT. BERT is really good at understanding and reading stories or any text you give him. When you ask BERT to read a sentence, he uses a special part of his brain called the “BERT Encoder” to understand it really well.
What is the BERT Encoder?
The BERT Encoder is like the robot’s super-smart brain that reads and understands sentences. It takes each word in a sentence and looks at it in the context of the words around it. This helps BERT figure out the meaning of the sentence more accurately.
How Does It Work?
- Reading Words Together: Imagine you give BERT a sentence like “The cat sat on the mat.” The BERT Encoder looks at each word one by one but also keeps in mind the whole sentence. It understands that “sat” is something the “cat” is doing, and “mat” is the place where the “cat” is sitting.
- Understanding Context: BERT Encoder is really good at understanding context. For example, if you say “bank,” it knows from the other words whether you’re talking about a riverbank or a place where you keep money.
- Learning from Lots of Sentences: BERT has read millions of sentences before, so his brain (the BERT Encoder) has learned a lot about how words usually go together. This makes him very smart at understanding new sentences you give him.
Why is it Useful?
The BERT Encoder is used in many computer programs that need to understand language, like:
- Search Engines: To understand what you’re looking for.
- Chatbots: To understand and respond to your questions.
- Translation Tools: To accurately translate sentences from one language to another.
Summary
The BERT Encoder is like a super-smart brain inside a robot named BERT. It reads and understands sentences by looking at all the words together and figuring out their meanings. This makes BERT really good at understanding and working with language, just like how you understand stories and conversations!

Moderate:
What is BERT?
BERT stands for Bidirectional Encoder Representations from Transformers. It’s a model developed by Google that has significantly advanced the field of natural language processing (NLP). BERT can understand the context of a word in a sentence by looking at the words that come before and after it, which makes it much better at understanding language than previous models.
What is the BERT Encoder?
The BERT Encoder is a key component of the BERT model. It’s responsible for processing and understanding the input text. Here’s a breakdown of its functions:
- Input Processing:
- BERT takes a piece of text and converts it into a format it can process, called tokens. This includes words and punctuation, which are broken down into smaller units. - Bidirectional Context:
- Unlike previous models that read text from left-to-right or right-to-left, the BERT Encoder reads the entire sentence at once, from both directions. This allows it to understand the context of each word more effectively. For example, in the sentence “The bank can hold the funds securely,” BERT can determine that “bank” refers to a financial institution because of the surrounding words. - Transformers:
- The BERT Encoder uses a type of neural network architecture called Transformers. Transformers are designed to handle sequences of data, like sentences, and they can capture the relationships between all words in the sentence, regardless of their position. - Layered Learning:
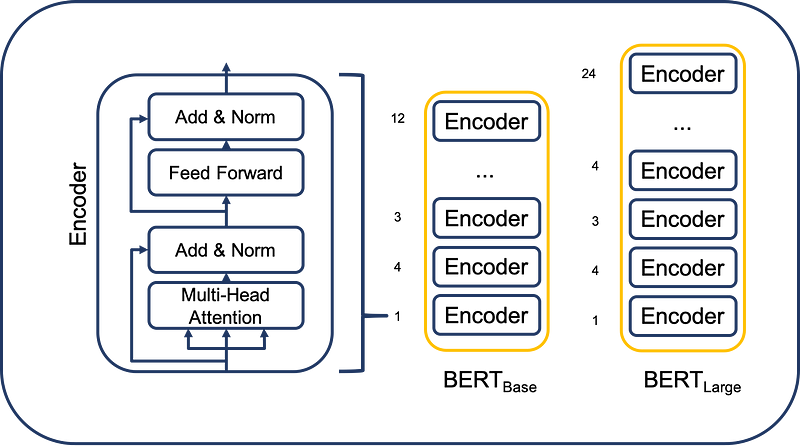
- The BERT Encoder is made up of multiple layers (often 12 or 24 in the base and large versions of BERT, respectively). Each layer refines the understanding of the text by focusing on different aspects of the words and their relationships.
How Does it Work?
- Tokenization:
- The input text is split into tokens and converted into numerical representations that the model can process. - Embedding:
- These tokens are then converted into vectors (arrays of numbers) through a process called embedding. This vector represents the meaning of the token in a form that the neural network can work with. - Attention Mechanism:
- The BERT Encoder uses an attention mechanism to weigh the importance of each word in the sentence. This helps the model focus on the words that are most relevant for understanding the meaning of the input text. - Encoding Layers:
- The vectors pass through multiple encoding layers. Each layer applies transformations that refine the understanding of the context around each word. - Output:
- The final output is a set of vectors, where each vector represents a word in the context of the entire sentence. These vectors can then be used for various NLP tasks like answering questions, classifying text, or generating new text.
Applications
The BERT Encoder is used in many NLP applications, such as:
- Search Engines: Improving the understanding of queries and retrieving more relevant results.
- Chatbots: Enhancing the ability to understand and respond to user queries.
- Translation: Providing more accurate translations by understanding the context better.
- Sentiment Analysis: Determining the sentiment of a piece of text (e.g., positive, negative, neutral).
Summary
The BERT Encoder is a sophisticated tool in deep learning that processes and understands text by considering the context of each word within a sentence. It uses a powerful architecture called Transformers to achieve this, allowing it to perform better in various NLP tasks. By processing text bidirectionally and through multiple layers, the BERT Encoder captures the nuanced meanings of words and their relationships in a way that was not possible with earlier models.
Hard:
BERT (Bidirectional Encoder Representations from Transformers) is a deep learning model that has revolutionized natural language processing (NLP) tasks. The BERT encoder is the core component of this model, responsible for understanding and representing the meaning of text input.
How BERT Encoder Works
- Tokenization: The input text is broken down into smaller units called tokens (words or subwords). Each token is assigned a unique numerical representation.
- Embedding: These tokens are then converted into dense vector representations called embeddings. These embeddings capture the semantic meaning and relationships between words.
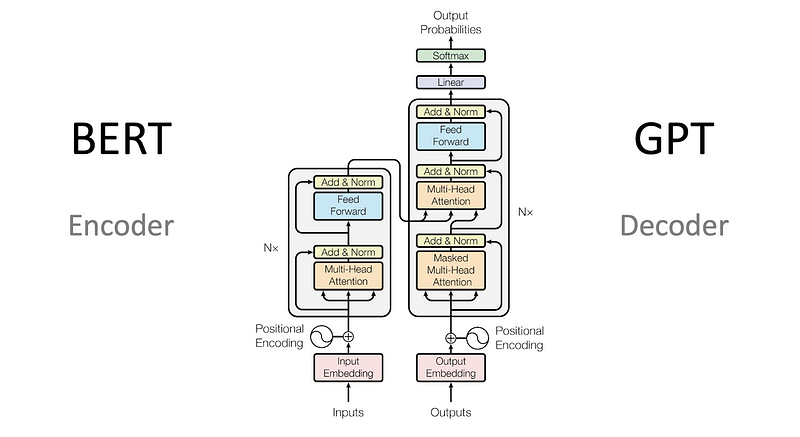
- Transformer Architecture: The heart of the BERT encoder is the Transformer architecture. It utilizes self-attention mechanisms to weigh the importance of different words in relation to each other. This allows the model to understand context and long-range dependencies in the text.
- Bidirectional Training: Unlike traditional language models that process text in one direction (left-to-right or right-to-left), BERT is trained bidirectionally. This means it considers both the preceding and following words when understanding the meaning of a specific word.
- Masked Language Modeling (MLM): During training, BERT randomly masks some tokens in the input text and tries to predict them based on the context. This helps the model learn a deeper understanding of language and relationships between words.
Output of BERT Encoder
The BERT encoder produces a sequence of contextualized embeddings, where each embedding represents a token in the input text. These embeddings encapsulate the rich information about the meaning of the words in the context of the sentence or document.
Applications of BERT Encoder
BERT’s powerful encoder has found numerous applications in NLP tasks, including:
- Text Classification: Determining the category or sentiment of a piece of text (e.g., spam detection, sentiment analysis).
- Named Entity Recognition (NER): Identifying and classifying named entities in text (e.g., person names, organizations, locations).
- Question Answering: Finding answers to questions posed in natural language.
- Machine Translation: Translating text from one language to another.
- Text Summarization: Generating concise summaries of longer texts.
Key Advantages of BERT Encoder
- Contextual Understanding: Captures the nuances of word meanings in different contexts.
- Bidirectional Training: Considers both preceding and following words for better understanding.
- Transformer Architecture: Enables efficient processing of long-range dependencies.
- Versatility: Adaptable to various NLP tasks with minimal task-specific modifications.
Overall, the BERT encoder is a powerful tool for natural language understanding, enabling machines to grasp the meaning and context of text more effectively. Its impact on NLP has been significant, paving the way for advancements in numerous language-related applications.
If you want you can support me: https://buymeacoffee.com/abhi83540
If you want such articles in your email inbox you can subscribe to my newsletter: https://abhishekkumarpandey.substack.com/
A few books on deep learning that I am reading:


Comments
Post a Comment